🧩 The Classic Problem: When a Service Doesn’t Respond
Imagine the following flow in a service-oriented system:
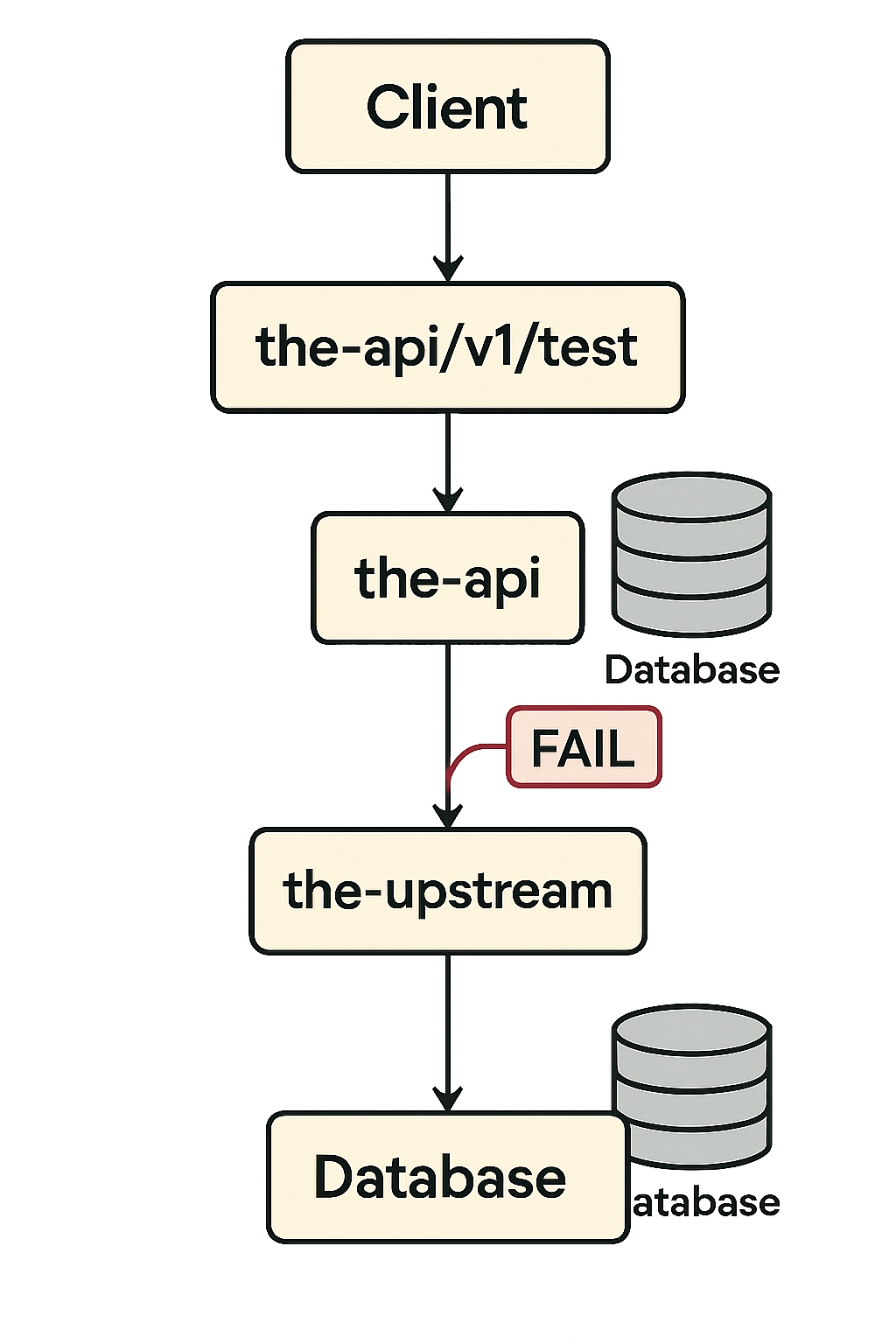
Client → the-api → the-upstream → Database
1️⃣ The client calls the-api/v1/test
2️⃣ the-api calls the-upstream
3️⃣ the-upstream writes data into its own database
4️⃣ It replies OK to the-api
5️⃣ the-api stores the result in its database and replies OK to the client
Everything works fine — until step 4 (D) fails because of a network partition or timeout.
Now, the-api doesn’t know if the upstream actually wrote the data or not.
You can’t safely commit your local write — and you can’t confidently reply to the client.
This is the ambiguous timeout problem, one of the hardest challenges in distributed systems.
🎯 The Goal
We need to ensure that:
- No operation executes twice (idempotency)
- No data is lost (durability)
- Every step is auditable
- The system remains useful even under partial failure (resilience)
🏗️ The Design Philosophy
The key is simple:
👉 First record the intent,
👉 Then attempt execution,
and if anything fails, have a way to reconcile later.
1️⃣ Operation ID and Idempotency
Each operation must have a unique identifier — created in the-api and passed along all downstream calls.
import uuid
from fastapi import FastAPI, Header, HTTPException
app = FastAPI()
@app.post("/v1/test")
async def test_endpoint(idempotency_key: str | None = Header(None)):
operation_id = idempotency_key or str(uuid.uuid7())
# Store operation as PENDING
print(f"New operation: {operation_id}")
...
👉 This ensures that if the same client retries due to a timeout, the system knows it’s the same operation, not a new one.
2️⃣ Persist Before Calling Upstream
the-api must persist the operation before invoking the external service to avoid dual-write problems.
from datetime import datetime
from sqlmodel import SQLModel, Field
class Operation(SQLModel, table=True):
id: str = Field(primary_key=True)
status: str = Field(default="PENDING")
created_at: datetime = Field(default_factory=datetime.utcnow)
updated_at: datetime = Field(default_factory=datetime.utcnow)
# Inside your handler
operation = Operation(id=operation_id)
session.add(operation)
session.commit()
If the process crashes right after this commit, the pending operation is still stored and can be retried later.
3️⃣ Resilient HTTP Client (Timeout + Retry + Circuit Breaker)
import httpx
from tenacity import retry, stop_after_attempt, wait_exponential_jitter
import pybreaker
breaker = pybreaker.CircuitBreaker(fail_max=5, reset_timeout=30)
@retry(stop=stop_after_attempt(3), wait=wait_exponential_jitter(1, 3))
@breaker
async def call_upstream(url: str, payload: dict, operation_id: str):
async with httpx.AsyncClient(timeout=httpx.Timeout(5.0, connect=3.0)) as client:
r = await client.post(url, json=payload, headers={"Idempotency-Key": operation_id})
r.raise_for_status()
return r.json()
📍 Explanation
- Timeout prevents blocking forever
- Retry with jitter handles transient errors
- Circuit Breaker isolates failing dependencies and prevents cascading failures
4️⃣ Handle Timeouts Gracefully — Respond 202 Accepted
If the upstream doesn’t respond, don’t lie to the client.
Return a 202 Accepted with the operation_id and a /status URL.
from fastapi.responses import JSONResponse
@app.post("/v1/test")
async def test_endpoint(idempotency_key: str | None = Header(None)):
operation_id = idempotency_key or str(uuid.uuid7())
try:
data = await call_upstream("https://upstream/api", {"foo": "bar"}, operation_id)
# Confirm and persist result
return {"status": "CONFIRMED", "operation_id": operation_id}
except Exception as exc:
# Mark as UNKNOWN and return 202
return JSONResponse(
{"status": "UNKNOWN", "operation_id": operation_id, "detail": str(exc)},
status_code=202,
)
Now the client can poll GET /v1/ops/{operation_id} until the operation is reconciled.
5️⃣ Reconciliation — Closing the Black Hole
A background worker periodically scans operations with status UNKNOWN and verifies whether the upstream succeeded.
from celery import Celery
celery_app = Celery(broker="redis://localhost")
@celery_app.task
def reconcile_operation(operation_id: str):
try:
result = call_upstream("https://upstream/status", {"op_id": operation_id}, operation_id)
if result.get("status") == "done":
mark_confirmed(operation_id)
else:
mark_failed(operation_id)
except Exception:
pass # retry later
💡 Common reconciliation sources
- Upstream provides
/status/{operation_id} - Webhooks from upstream
- Daily batch exports or financial statements
6️⃣ Ledger and Compensation
When the upstream is a true black box, you can’t know for sure whether it executed (C).
In that case, you need compensating entries, not deletions — especially for financial data.
class LedgerEntry(SQLModel, table=True):
id: str = Field(primary_key=True)
operation_id: str
account: str
amount: float
direction: str # "DR" or "CR"
created_at: datetime = Field(default_factory=datetime.utcnow)
If you detect a duplicate or invalid operation:
def compensate(entry: LedgerEntry):
reverse = LedgerEntry(
id=str(uuid.uuid7()),
operation_id=entry.operation_id,
account=entry.account,
amount=entry.amount,
direction="CR" if entry.direction == "DR" else "DR",
)
session.add(reverse)
session.commit()
💬 In finance, you never delete — you offset.
7️⃣ Outbox Pattern — Guaranteed Delivery
The outbox pattern ensures events are published even if the process crashes after committing the transaction.
class OutboxEvent(SQLModel, table=True):
id: str = Field(primary_key=True)
aggregate: str
payload: str
published_at: datetime | None = None
def create_operation(payload):
operation = Operation(id=payload["op_id"], status="PENDING")
outbox = OutboxEvent(aggregate="operation", payload=json.dumps(payload))
with session.begin():
session.add(operation)
session.add(outbox)
A separate worker scans the outbox and sends events to a message broker (e.g., Kafka, RabbitMQ, or Celery).
8️⃣ Sagas — Orchestrating Multi-Step Consistency
For multi-service transactions, use the Saga pattern:
each step has a compensating action if the next one fails.
from dataclasses import dataclass, field
from typing import Awaitable, Callable
StepFn = Callable[[], Awaitable[None]]
CompFn = Callable[[], Awaitable[None]]
@dataclass
class Step:
do: StepFn
compensate: CompFn
@dataclass
class Saga:
steps: list[Step] = field(default_factory=list)
async def execute(self):
done = []
try:
for s in self.steps:
await s.do()
done.append(s)
except Exception:
for s in reversed(done):
await s.compensate()
raise
Example: create order → reserve stock → charge payment.
If payment fails, cancel stock and cancel order.
✅ Final Checklist
| Pattern | Purpose |
|---|---|
| Operation ID | Unique identity per transaction |
| Idempotency | Avoid duplicate effects |
| Timeout + Retry + Breaker | Network resilience |
| Persist-before-call | Auditability |
| Outbox + Worker | Guaranteed delivery |
| 202 + /status | Transparent uncertainty |
| Reconciliation | Close ambiguous states |
| Ledger | Compensate instead of deleting |
| Sagas | Cross-service consistency |
📈 Observability and Metrics
Track these KPIs to keep your system healthy:
- p95 latency per upstream call
- % of timeouts
- Number and age of
UNKNOWNoperations - Circuit breaker open duration
- Outbox/DLQ backlog
- % of compensated operations
📚 Recommended Reading
- Designing Data-Intensive Applications — Martin Kleppmann
- Microservices Patterns — Chris Richardson
- Stripe Engineering Blog: Idempotency in APIs
- Google SRE Workbook
💬 Have you ever faced this “ambiguous timeout” issue?
How did you solve it in your system?
Share your thoughts or tag me on LinkedIn with #CleanArchitecture #Microservices.